前言
应用程序在跟驱动程序之间传递数据的时候,如果是通过read和write来进行的话,涉及到用户态跟内核态之间的数据传输,要走copy_from_user跟copy_to_user的数据拷贝。假设如果每次App给Kernel传的数据比较多,比如几MB,这样数据传输效率会比较低,改进方法是通过mmap来实现,把内核的buffer映射到用户态,App直接在用户态进行读写操作。
实现过程
实现过程分为应用层跟驱动层来讲。假设现在的场景是,有一个8KB的buffer需要来传数据。
应用层
应用层的实现并不复杂,打开节点,然后用mmap函数就可以得到一段映射出来的buf了,这里主要讲mmap函数如何用,可以在Linux输入man mmap查看
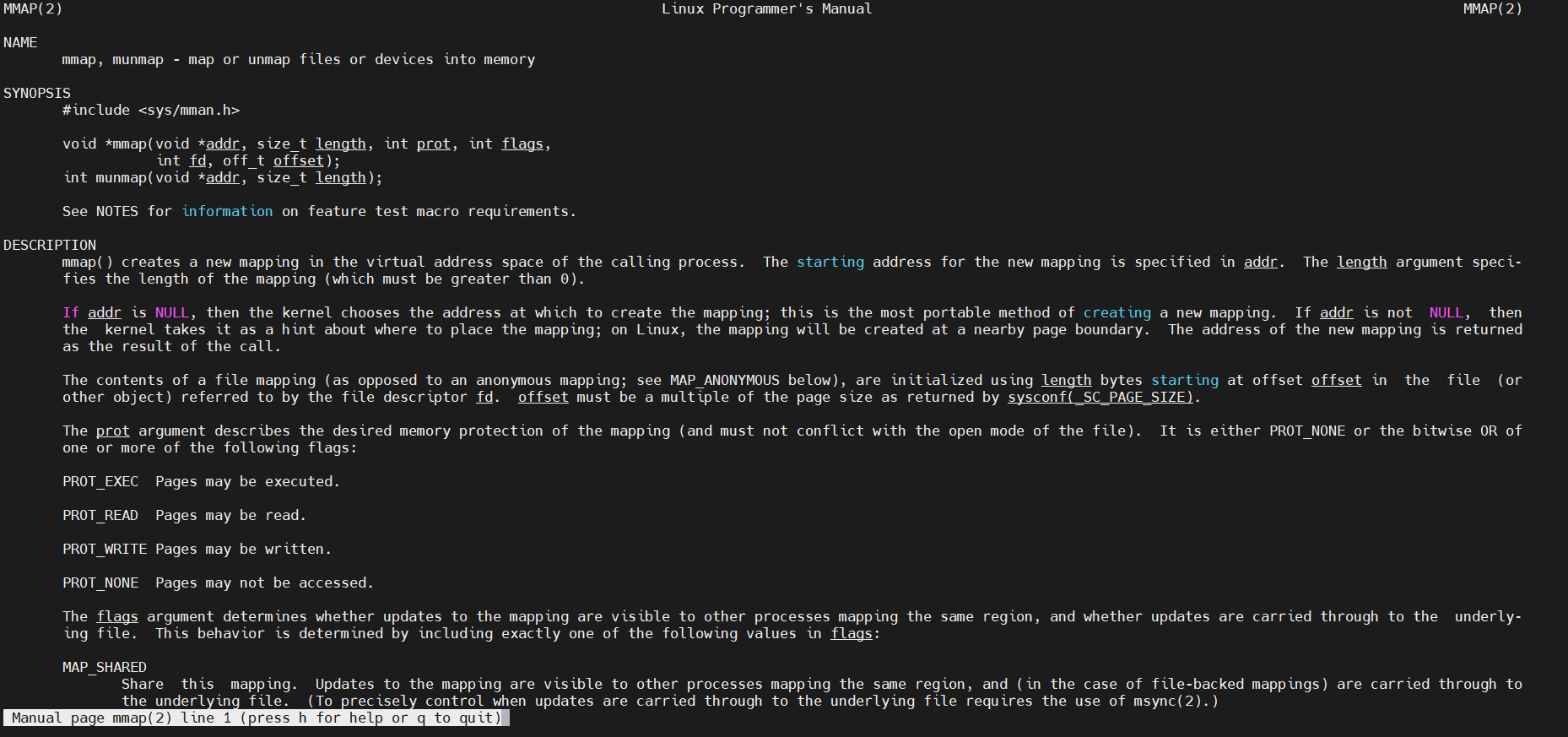
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
addr:指向欲映射的内存起始地址,通常设为 NULL,代表让系统自动选定地址length:代表要映射多大的内存,以字节为单位prot:映射区域的保护方式,可以由一下四种方式来进行组合(进行或运算)PROT_EXEC:映射区域可被执行PROT_EXEC:映射区域可被读取PROT_EXEC:映射区域可被写入PROT_EXEC:映射区域不能存取
flags:影响映射区域的各种特性(有好几个类型,这里就介绍几个常用的)MAP_SHARED:对映射区域的写入数据会复制回文件内,而且允许其他映射该文件的进程共享MAP_PRIVATE:对映射区域的写入操作会产生一个映射文件的复制,即私人的“写入时复制”(copy on write)对此区域作的任何修改都不会写回原来的文件内容MAP_ANONYMOUS:建立匿名映射。此时会忽略参数fd,不涉及文件,而且映射区域无法和其他进程共享
fd:一般是驱动生成的节点offset:文件映射的偏移量,通常设置为0,代表从文件最前方开始对应,offset必须是分页大小的整数倍
既然有映射,那肯定也有解映射,看函数的原型跟参数也差不多是什么意思这里就不赘述了
int munmap(void *addr, size_t length);
驱动层
驱动层这边主要做的就是,先分配一块8kB的内存,然后提供mmap函数,完成内存映射的任务。分配一块8kB的内存,这个可以在驱动初始化的时候做,这里就不赘述了。mmap函数部分,先贴个简单的demo代码。
static int mmap_test_dev_drv_mmap(struct file *file, struct vm_area_struct *vma)
{
/* 获得物理地址 */
unsigned long phy = virt_to_phys(kernel_mmap_buf);
/* 设置属性: cache, buffer */
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
/* map */
if (remap_pfn_range(vma, vma->vm_start, phy >> PAGE_SHIFT,
vma->vm_end - vma->vm_start, vma->vm_page_prot)) {
printk("mmap remap_pfn_range failed\n");
return -ENOBUFS;
}
return 0;
}
这个demo实现的比较简单,流程如下:先申请8kB的kernel_mmap_buf->将我们前面申请到的8kB的kernel_mmap_buf进行虚拟地址到物理地址的转换->对vm_area_struct设置其属性(cache, buffer)->然后进行内存映射。流程虽然简单,但是其中的细节还需要深究。
申请内存
在这里我们分配一块8KB的内存,需要是连续的,这样子应用层mmap后才能使用一个基地址去访问这块内存。由下表知道最好还是选择kmalloc啦。

kernel_mmap_buf = kmalloc(1024*8, GFP_KERNEL);
vm_area_struct
我们可以看到mmap函数的原型,有个入参vm_area_struct,这个入参是什么作用呢?
int (*mmap) (struct file *, struct vm_area_struct *);
linux内核使用vm_area_struct结构来表示一个独立的虚拟内存区域,由于每个不同质的虚拟内存区域功能和内部机制都不同,因此一个进程使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。各个vm_area_struct结构使用链表或者树形结构链接,方便进程快速访问,如下图所示:
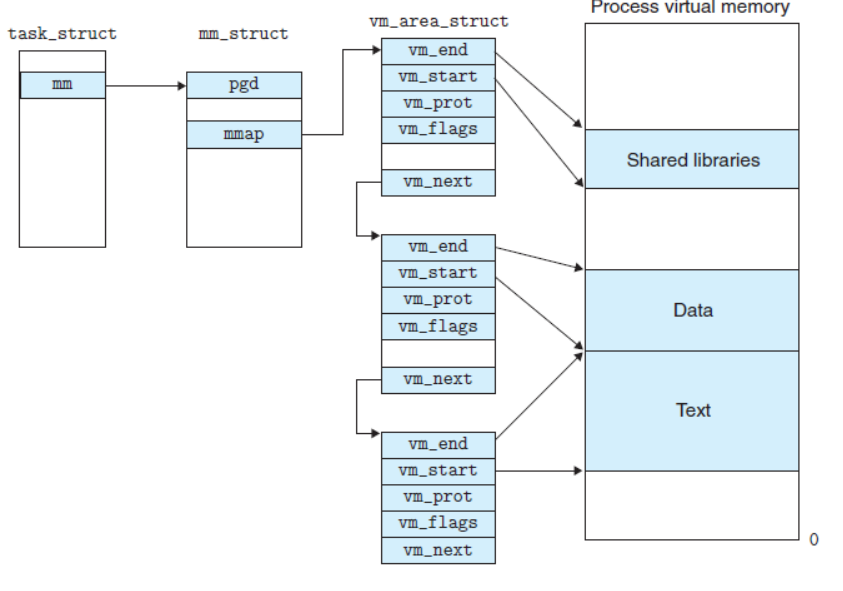
引用的这段话中,所谓的每个不同质的虚拟内存区域功能和内部机制都不同,因此一个进程使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域,用我自己的理解就是,譬如上图的,有的vma_area_struct结构指向一个程序中共享的动态库,有的指向代码段,有的指向text段,大概是这个意思。
那知道了vma_area_struct是用来做什么的,那上图中前面的那些结构体是做什么用的呢?下面就稍微的讲下
task_struct , mm_struct ,vma_area_struct三者之间的关系
每一个APP在内核里都有一个 tast_struct,这个结构体中保存有内存信息:mm_struct。而虚拟地址、 物理地址的映射关系保存在页目录表中,如下图所示:
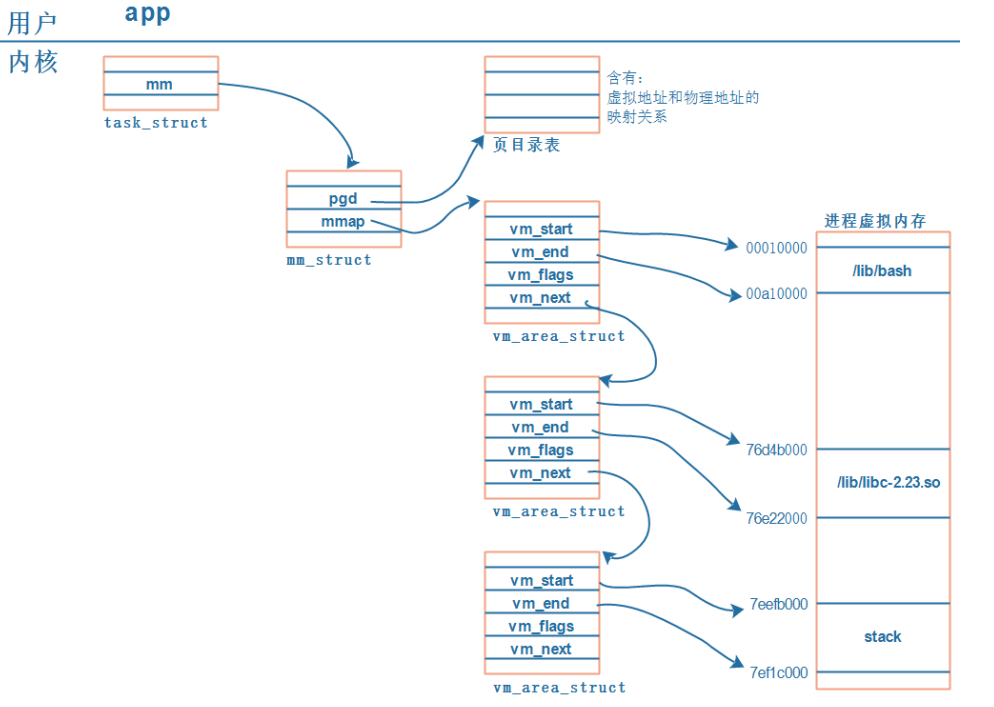
- 每个
APP在内核中都有一个task_struct结构体,它用来描述一个进程 - 每个
APP都要占据内存,在task_struct中用mm_struct来管理进程占用的内存; 内存有虚拟地址、物理地址,mm_struct中用mmap来描述虚拟地址,用pgd来描述对应的物理地址。(pgd,Page Global Directory,页目录。) - 每个
APP都有一系列的VMA:virtual memory比如APP含有代码段、数据段、BSS段、栈等等,还有共享库。这些单元会保存在内存里,它们的地址空间不同,权限不同(代码段是只读的可运行的、数据段可读可写),内核用一系列的vm_area_struct来描 述它们。vm_area_struct中的vm_start、vm_end是虚拟地址。 vm_area_struct中虚拟地址如何映射到物理地址去? 每一个APP的虚拟地址可能相同,物理地址不相同,这些对应关系保存在pgd中。
ARM 中cache , write buffer(写缓冲器 )相关的知识
在上面的流程第二步提到了要设置属性,这里有两个概念,cache跟写缓冲器 write buffer。
/* 设置属性: cache, buffer */
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
这里就简单的介绍下相关的知识。
下图是CPU 和内存之间的关系,有 cache、buffer(写缓冲器)。Cache是一块高速内存;写缓冲器相当于一个FIFO,可以把多个写操作集合起来一次写入内存。
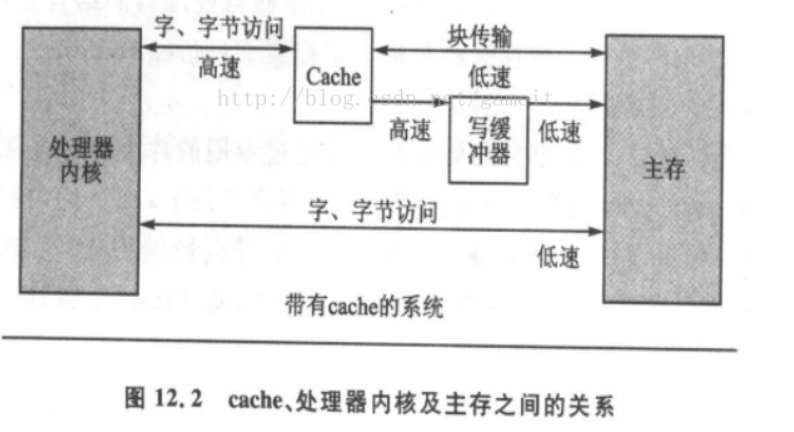
是否使用 cache,是否使用 buffer,就有 4 种组合,内核文件arch/arm/include/asm/pgtable-2level.h有如下宏定义
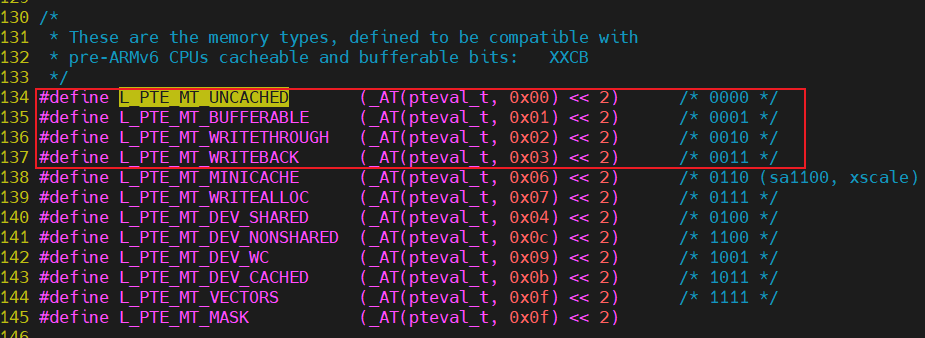
#define L_PTE_MT_UNCACHED (_AT(pteval_t, 0x00) << 2) /* 0000 */
#define L_PTE_MT_BUFFERABLE (_AT(pteval_t, 0x01) << 2) /* 0001 */
#define L_PTE_MT_WRITETHROUGH (_AT(pteval_t, 0x02) << 2) /* 0010 */
#define L_PTE_MT_WRITEBACK (_AT(pteval_t, 0x03) << 2) /* 0011 */
对于启用cache跟启用buffer的简单说明,不过这里先说下cache hit概念:CPU要访问的数据在Cache中有缓存,称为“命中” (Hit),反之则称为“缺失” (Miss)。
| 是否启用cache | 是否启用buffer | 说明 |
|---|---|---|
| 0 | 0 | Non-cached, non-buffered (NCNB) 读、写都直达外设硬件 任何对memory的读写都反映到总线上,对 memory 的操作过程中CPU需要等待 |
| 0 | 1 | Non-cached buffered (NCB) 读、写都直达外设硬件 写操作通过 buffer 实现,CPU 不等待写操作完成,CPU 会马上执行下一条指令 读操作直接反映到总线上;写操作,CPU将数据写入到写缓冲后继续运行,由写缓冲进行写回操作 |
| 1 | 0 | Cached, write-through mode (WT),写通 读:cache hit 时从 cache 读数据;cache miss 时已入一行 数据到 cache; 写:通过 buffer 实现,CPU 不等待写操作完成,CPU 会马上执行下一条指令 读操作首先考虑cache hit;写操作时直接将数据写入写缓冲,如果同时出现cache hit,那么也更新cache |
| 1 | 1 | Cached, write-back mode (WB),写回 读:cache hit 时从 cache 读数据;cache miss 时已入一行数据到 cache; 写:通过 buffer 实现,cache hit 时新数据不会到达硬件, 而是在 cahce 中被标为“脏”;cache miss 时,通过 buffer 写入硬件,CPU 不等待写操作完成,CPU 会马上执行下一条指 令 读操作首先考虑cache hit;写操作也首先考虑cache hit |
- 第
1种是不使用cache也不使用buffer,读写时都直达硬件,这适合寄存器的读写。 - 第
2种是不使用cache但是使用buffer,写数据时会用buffer进行优化,可能会有“写合并”,这适合显存的操作。因为对显存很少有读操作,基本都是写操作,而写操作即使被“合并”也没有关系。 - 第
3种是使用cache不使用buffer,就是“write through”,适用于只读设备:在读数据时用cache加速,基本不需要写。 - 第
4种是既使用cache又使用buffer,适合一般的内存读写。
回归正题,我们是从设置属性的时候才引入cache和buffer相关知识的介绍
/* 设置属性: cache, buffer */
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
虽然前面说了有四个组合,但是我在内核中貌似就找到了常用的下面的两个设置属性的函数
pgprot_writecombine:禁止了B(Bufferable)域pgprot_noncached:禁止了页表项中的C(Cacheable)域和B(Bufferable)域
映射
第三个流程就是映射,用到remap_pfn_range函数
/* map */
if (remap_pfn_range(vma, vma->vm_start, phy >> PAGE_SHIFT,
vma->vm_end - vma->vm_start, vma->vm_page_prot)) {
printk("mmap remap_pfn_range failed\n");
return -ENOBUFS;
}
由kernel官网找到的关于remap_pfn_range的解释:
remap_pfn_range — remap kernel memory to userspace
翻译过来就是:将内核空间的内存映射到用户空间
要注意的是,remap_pfn_range 中,pfn 的意思是“Page Frame Number”,是虚拟地址应该映射到的物理地址的页面号。假设每页大小是 4K,那么给定物理地址 phy,它的 pfn = phy / 4096 = phy » 12。内核的 page 一般是 4K,但是也可以配置内核修改 page 的大 小。所以为了通用,pfn = phy » PAGE_SHIFT。
mmap从应用层到驱动层的一个过程
主要调用过程如下图所示
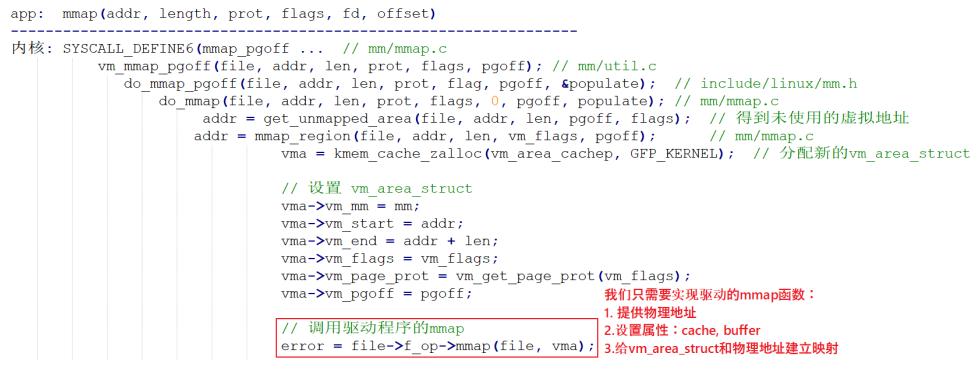
其中有个关键点可以简单的说下:应用层调用mmap函数时,到底层内核会帮我们构造一个vm_area_struct结构体
示例代码
自己仿照视频写了个很简单的demo,大概就是验证下映射的buf是不是能操作,没有去做过多的其他验证,比较简单,视频里面的原代码在下面也给出
应用层
mmap_test.c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <sys/mman.h>
#include <unistd.h>
int main(void)
{
int fd;
unsigned char * mmap_buf;
fd = open("/dev/mmap_test_dev",O_RDWR);
if (fd < 0)
{
perror("cannot open /dev/mmap_test_dev\n");
return -1;
}
/*申请8KB*/
mmap_buf = mmap(NULL,1024*8,PROT_WRITE|PROT_READ,MAP_SHARED,fd,0);
if (MAP_FAILED == mmap_buf)
{
perror("cannot mmap\n");
return -1;
}
printf("mmap_buf now is mmap sucessfully,its original story is :\n%s\n",mmap_buf);
printf("mmap_buf virtual addr is 0x%p \n",mmap_buf);
strcpy(mmap_buf,"this line is from app");
printf("app write mmapbuf something\n");
printf("mmap_buf now story is :%s\n",mmap_buf);
sleep(30); /* cat /proc/pid/maps */
munmap(mmap_buf, 1024*8);
close(fd);
}
驱动层
mmap_drv.c
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/errno.h>
#include <linux/miscdevice.h>
#include <linux/kernel.h>
#include <linux/major.h>
#include <linux/mutex.h>
#include <linux/proc_fs.h>
#include <linux/seq_file.h>
#include <linux/stat.h>
#include <linux/init.h>
#include <linux/device.h>
#include <linux/tty.h>
#include <linux/kmod.h>
#include <linux/gfp.h>
#include <asm/pgtable.h>
#include <linux/mm.h>
#include <linux/slab.h>
static char *kernel_mmap_buf;
struct miscdevice mmap_dev_pointer;
#define MIN(a, b) (a < b ? a : b)
static ssize_t mmap_test_dev_drv_read (struct file *file, char __user *buf, size_t size, loff_t *offset)
{
return MIN(1024, size);
}
static ssize_t mmap_test_dev_drv_write (struct file *file, const char __user *buf, size_t size, loff_t *offset)
{
return MIN(1024, size);
}
static int mmap_test_dev_drv_mmap(struct file *file, struct vm_area_struct *vma)
{
/* 获得物理地址 */
unsigned long phy = virt_to_phys(kernel_mmap_buf);
/* 设置属性: cache, buffer */
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
/* map */
if (remap_pfn_range(vma, vma->vm_start, phy >> PAGE_SHIFT,
vma->vm_end - vma->vm_start, vma->vm_page_prot)) {
printk("mmap remap_pfn_range failed\n");
return -ENOBUFS;
}
return 0;
}
static int mmap_test_dev_drv_open (struct inode *node, struct file *file)
{
return 0;
}
static int mmap_test_dev_drv_close (struct inode *node, struct file *file)
{
return 0;
}
static struct file_operations mmap_test_dev_drv = {
.owner = THIS_MODULE,
.open = mmap_test_dev_drv_open,
.read = mmap_test_dev_drv_read,
.write = mmap_test_dev_drv_write,
.release = mmap_test_dev_drv_close,
.mmap = mmap_test_dev_drv_mmap,
};
static int __init mmap_test_dev_init(void)
{
int ret = 0;
mmap_dev_pointer.minor = MISC_DYNAMIC_MINOR;
mmap_dev_pointer.name = "mmap_test_dev";
mmap_dev_pointer.fops = &mmap_test_dev_drv;
ret = misc_register(&mmap_dev_pointer);
if (ret) {
pr_err( "Cannot register miscdev on minor=%d (err=%d)\n", MISC_DYNAMIC_MINOR, ret);
return ret;
}
kernel_mmap_buf = kmalloc(1024*8, GFP_KERNEL);
strcpy(kernel_mmap_buf, "this line is from kernel");
pr_info("kernel_map_buf is initilized with :%s\n",kernel_mmap_buf);
return 0;
}
static void __exit mmap_test_dev_exit(void)
{
misc_deregister(&mmap_dev_pointer);
kfree(kernel_mmap_buf);
}
module_init(mmap_test_dev_init);
module_exit(mmap_test_dev_exit);
MODULE_LICENSE("GPL");
结果
加载驱动

运行应用层程序,通过命令cat /proc/进程PID/maps可以查看查看进程的虚拟地址是怎么使用的。
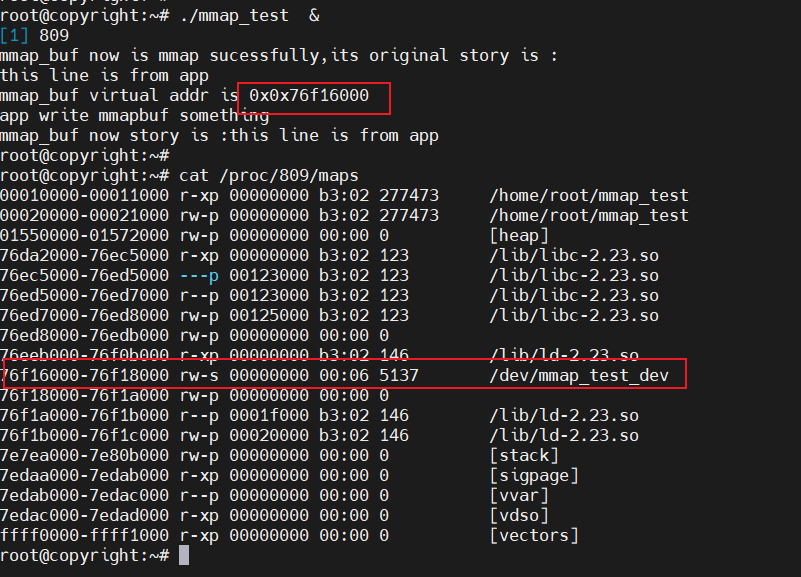
像图中的红框,rw-s不就刚好对应之前应用层代码设置的PROT_WRITE|PROT_READ,MAP_SHARED,然后之前设置的偏移量是0,kernel_mmap_buf的虚拟地址是76f16000,是不是刚好就对应76f16000
76f16000-76f18000 rw-s 00000000 00:06 5137 /dev/mmap_test_dev
接着再看这一行,rw-p中的p其实代表的是MMAP_PRIVATE,因为在Linux中多个进程会使用同一个动态库,在没有写操作之前大家都使用内存中唯一一份代码。当进程A发起写操作时,内核会为它复制一份代码,再执行写操作,进程A就有了专享的、私有的动态库,在里面做的修改只会影响到 进程A。其他程序仍然共享原先的、未修改的代码。
76ed7000-76ed8000 rw-p 00125000 b3:02 123 /lib/libc-2.23.so
链接
视频源代码
hello_drv_test.c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <sys/mman.h>
#include <unistd.h>
/*
* ./hello_drv_test
*/
int main(int argc, char **argv)
{
int fd;
char *buf;
int len;
char str[1024];
/* 1. 打开文件 */
fd = open("/dev/hello", O_RDWR);
if (fd == -1)
{
printf("can not open file /dev/hello\n");
return -1;
}
/* 2. mmap
* MAP_SHARED : 多个APP都调用mmap映射同一块内存时, 对内存的修改大家都可以看到。
* 就是说多个APP、驱动程序实际上访问的都是同一块内存
* MAP_PRIVATE : 创建一个copy on write的私有映射。
* 当APP对该内存进行修改时,其他程序是看不到这些修改的。
* 就是当APP写内存时, 内核会先创建一个拷贝给这个APP,
* 这个拷贝是这个APP私有的, 其他APP、驱动无法访问。
*/
buf = mmap(NULL, 1024*8, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (buf == MAP_FAILED)
{
printf("can not mmap file /dev/hello\n");
return -1;
}
printf("mmap address = 0x%x\n", buf);
printf("buf origin data = %s\n", buf); /* old */
/* 3. write */
strcpy(buf, "new");
/* 4. read & compare */
/* 对于MAP_SHARED映射: str = "new"
* 对于MAP_PRIVATE映射: str = "old"
*/
read(fd, str, 1024);
if (strcmp(buf, str) == 0)
{
/* 对于MAP_SHARED映射,APP写的数据驱动可见
* APP和驱动访问的是同一个内存块
*/
printf("compare ok!\n");
}
else
{
/* 对于MAP_PRIVATE映射,APP写数据时, 是写入原来内存块的"拷贝"
*/
printf("compare err!\n");
printf("str = %s!\n", str); /* old */
printf("buf = %s!\n", buf); /* new */
}
while (1)
{
sleep(10); /* cat /proc/pid/maps */
}
munmap(buf, 1024*8);
close(fd);
return 0;
}
hello_drv.c
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/errno.h>
#include <linux/miscdevice.h>
#include <linux/kernel.h>
#include <linux/major.h>
#include <linux/mutex.h>
#include <linux/proc_fs.h>
#include <linux/seq_file.h>
#include <linux/stat.h>
#include <linux/init.h>
#include <linux/device.h>
#include <linux/tty.h>
#include <linux/kmod.h>
#include <linux/gfp.h>
#include <asm/pgtable.h>
#include <linux/mm.h>
#include <linux/slab.h>
/* 1. 确定主设备号 */
static int major = 0;
static char *kernel_buf;
static struct class *hello_class;
static int bufsiz = 1024*8;
#define MIN(a, b) (a < b ? a : b)
/* 3. 实现对应的open/read/write等函数,填入file_operations结构体 */
static ssize_t hello_drv_read (struct file *file, char __user *buf, size_t size, loff_t *offset)
{
int err;
printk("%s %s line %d\n", __FILE__, __FUNCTION__, __LINE__);
err = copy_to_user(buf, kernel_buf, MIN(bufsiz, size));
return MIN(bufsiz, size);
}
static ssize_t hello_drv_write (struct file *file, const char __user *buf, size_t size, loff_t *offset)
{
int err;
printk("%s %s line %d\n", __FILE__, __FUNCTION__, __LINE__);
err = copy_from_user(kernel_buf, buf, MIN(1024, size));
return MIN(1024, size);
}
static int hello_drv_mmap(struct file *file, struct vm_area_struct *vma)
{
/* 获得物理地址 */
unsigned long phy = virt_to_phys(kernel_buf);
/* 设置属性: cache, buffer */
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
/* map */
if (remap_pfn_range(vma, vma->vm_start, phy >> PAGE_SHIFT,
vma->vm_end - vma->vm_start, vma->vm_page_prot)) {
printk("mmap remap_pfn_range failed\n");
return -ENOBUFS;
}
return 0;
}
static int hello_drv_open (struct inode *node, struct file *file)
{
printk("%s %s line %d\n", __FILE__, __FUNCTION__, __LINE__);
return 0;
}
static int hello_drv_close (struct inode *node, struct file *file)
{
printk("%s %s line %d\n", __FILE__, __FUNCTION__, __LINE__);
return 0;
}
/* 2. 定义自己的file_operations结构体 */
static struct file_operations hello_drv = {
.owner = THIS_MODULE,
.open = hello_drv_open,
.read = hello_drv_read,
.write = hello_drv_write,
.release = hello_drv_close,
.mmap = hello_drv_mmap,
};
/* 4. 把file_operations结构体告诉内核:注册驱动程序 */
/* 5. 谁来注册驱动程序啊?得有一个入口函数:安装驱动程序时,就会去调用这个入口函数 */
static int __init hello_init(void)
{
int err;
kernel_buf = kmalloc(bufsiz, GFP_KERNEL);
strcpy(kernel_buf, "old");
printk("%s %s line %d\n", __FILE__, __FUNCTION__, __LINE__);
major = register_chrdev(0, "hello", &hello_drv); /* /dev/hello */
hello_class = class_create(THIS_MODULE, "hello_class");
err = PTR_ERR(hello_class);
if (IS_ERR(hello_class)) {
printk("%s %s line %d\n", __FILE__, __FUNCTION__, __LINE__);
unregister_chrdev(major, "hello");
return -1;
}
device_create(hello_class, NULL, MKDEV(major, 0), NULL, "hello"); /* /dev/hello */
return 0;
}
/* 6. 有入口函数就应该有出口函数:卸载驱动程序时,就会去调用这个出口函数 */
static void __exit hello_exit(void)
{
printk("%s %s line %d\n", __FILE__, __FUNCTION__, __LINE__);
device_destroy(hello_class, MKDEV(major, 0));
class_destroy(hello_class);
unregister_chrdev(major, "hello");
kfree(kernel_buf);
}
/* 7. 其他完善:提供设备信息,自动创建设备节点 */
module_init(hello_init);
module_exit(hello_exit);
MODULE_LICENSE("GPL");
后话
这次的学习笔记还是比较浅显的,还有其他的点可以去深挖的,比如用户态的mmap的地方,这个链接里面讲到了,除了MAP_PRIVATE 这种用的比较少的情况,还有MAP_ANONYMOUS建立匿名映射的这种用法,比较复杂,但是要是在前面讲就越写越多了,反而写的太多,记得太多,把最常用的也有可能给搞混了,忘了,这样就得不偿失了。
然后再搜索相关资料的时候,发现mmap操作可以通过将硬件的寄存器地址在用户态传入offset来控制硬件???不是很懂其中的原理,如果后续有时间可以看看。
关于应用层的map_private,其实视频中给的例子是很不错的,所以我这里也不再赘述了。